
A decade ago, sharing a computation implied providing code and data related to the application. There is increasing consensus that to establish the reproducibility of results, authors must also share a description of their computing environments, such as documentation of system libraries, configuration files, and parameters used. Containerization has emerged as a predominant technology for preserving and sharing computational environments. But is containerization sufficient?
The DICE lab is building advanced containers that combine isolation property offered by containers with data provenance and analysis methods. We are building a variety of containers for data-intensive applications, interactive applications, and analytical applications.

Sciunits are efficient, lightweight, self-contained packages of computational experiments that can be guaranteed to repeat or reproduce regardless of deployment issues. Sciunit answers the call for a reusable research object that containerizes and stores applications simply and efficiently, facilitates sharing and collaboration, and eases the task of executing, understanding, and building on shared work. To create Sciunits, install our Linux command-line tool.
Sciunits: Reusable Research Objects. Ton That DH. Fils, G. Yuan, Z. Malik, T. , 2017 IEEE 13th International Conference on e-Science (e-Science), 2017. Paper
An invariant framework for conducting reproducible computational science. Meng, H. Kommineni, R. Pham, Q. Gardner, R. Malik, T. Thain, D. , Journal of Computational Science, 2015. Paper
SOLE: towards descriptive and interactive publications. Malik, T. Pham, Q. Foster, I. T. Leisch, F. Peng, R. , Implementing reproducible research, 2014. Paper
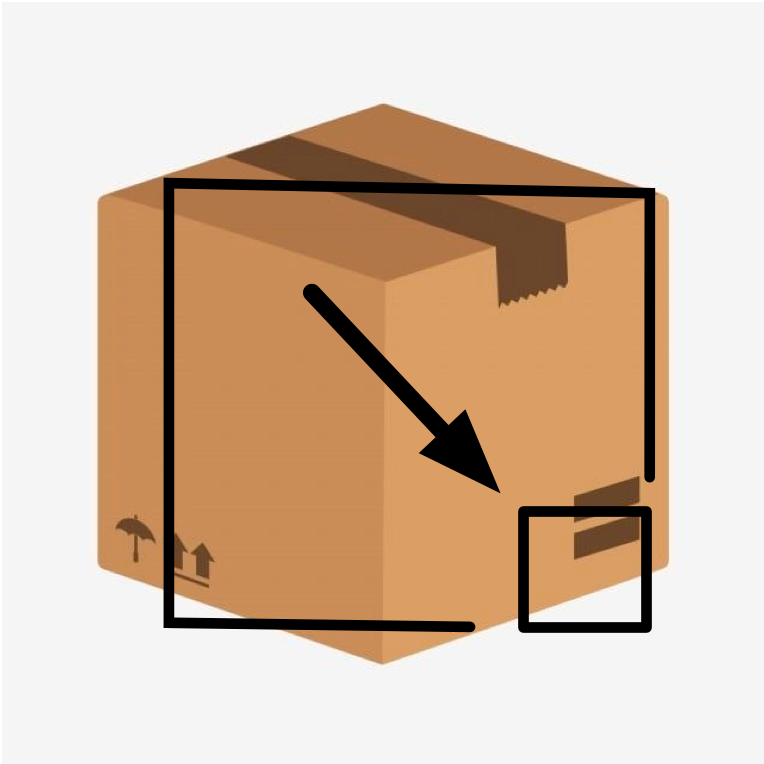
Containerization simplifies the sharing and deployment of applications when environments change in the software delivery chain. To deploy an application, container delivery methods push and pull container images. These methods operate on file and layer (set of files) granularity, and introduce redundant data within a container. Several container operations such as upgrading, installing, and maintaining become inefficient, because of copying and provisioning of redundant data. CDMT is a content-defined Merkle Tree for deduplicated storage used in containers. CDMT indexes deduplicated and determines changes to blocks in logarithmic time on the client. CDMT efficiently pushes and pulls container images from a registry, especially as containers are upgraded and (re-)provisioned on a client. A registry can efficiently maintain the CDMT index as new image versions are pushed. CDMT are more scalable than Merkle Trees in terms of disk and network I/O savings ias shown using 15 container images and 233 image versions from Docker Hub.
Content-defined Merkle Trees for Efficient Container Delivery. Nakamura, Y. Ahmad, R. Malik, T. 28th IEEE International Conference on High Performance Computing, Data, & Analytics, 2020. Paper
Scientific applications often depend on data produced from computational models. Model-generated data can be prohibitively large. Current mechanisms for sharing and distributing reproducible applications, such as containers, assume all model data is saved and included with a program to support its successful re-execution. However, including model data increases the sizes of containers. This increases the cost and time required for deployment and further reuse. MiDAS ( Minimizing Datasets) is a framework for specializing I/O libraries which, given an application, automates the process of identifying and including only a subset of the data accessed by the program. To do this, MiDas combines static and dynamic analysis techniques to map high level user inputs to low level file offsets.
MiDas: Containerizing Data-Intensive Applications with I/O Specialization. Niddodi, C. Gehani, A. Malik, T. Navas, J. A. Mohan, S. , Proceedings of the 3rd International Workshop on Practical Reproducible Evaluation of Computer Systems, 2020. Paper

The conduct of reproducible science improves when computations are portable and verifiable. A container runtime provides an isolated environment for running computations and thus is useful for porting applications on new machines. Current container engines, such as LXC and Docker, however, do not track provenance, which is essential for verifying computations. SciInc is a container runtime that tracks the provenance of computations during container creation. SciInc container engines can use audited provenance data for efficient container replay. SciInc observes inputs to computations, and, if they change, propagates the changes, re-using partially memoized computations and data that are identical across replay and original run.
SciInc: A Container Runtime for Incremental Recomputation. Youngdahl, A. Ton-That, D. Malik, T. 2019 15th International Conference on eScience (eScience), 2019. Paper

Light-weight database virtualization (LDV) is a system that allows users to share and re-execute applications that operate on a relational database (DB). Previous methods for sharing DB applications, such as companion websites and virtual machine images (VMIs), support neither easy and efficient re-execution nor the sharing of only a relevant DB subset. LDV addresses these issues by monitoring application execution, including DB operations, and using the resulting execution trace to create a lightweight re-executable package. A LDV package includes, in addition to the application, either the DB management system (DBMS) and relevant data or, if the DBMS and/or data cannot be shared, just the application-DBMS communications for replay during re-execution. LDV uses a linked DB-operating system provenance model and show how to infer data dependencies based on temporal information.
LDV: Light-weight database virtualization. Pham, Q. Malik, T. Glavic, B. Foster, I. 2015 IEEE 31st International Conference on Data Engineering, 2015. Paper
Thanks to Boris Glavic</a> for the LDV logo.This work is supported by the NSF through grants CNS-1846418, ICER-1928369, ICER-1639759, and BSSw Fellowship;





