
Data provenance, is about methodically recording a computation. Our research work is examining different approaches to see how data provenance can optimise re-computation in the presence of changes. This can improve use of provenance in a variety of purposes, including facilitating experiment reproducibility, distributed debugging, and efficiently replay when sharing data and code. Specific research questions include (1) how, and under what assumptions, can re-computation be optimized using incremental and/or partial processing techniques, and (2) how do we determine the impact of a set of changes on the outcomes, in order to decide when changes should trigger recomputations. We optimize recomputation while computing differences, alignment, and during replay.
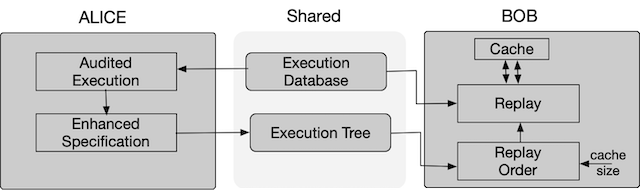
In scientific computing and data science disciplines, it is often necessary to share application workflows and repeat results. Current tools containerize application workflows, and share the resulting container for repeating results. These tools, due to containerization, do improve sharing of results. However, they do not improve the efficiency of replay. The multiversion replay problem arises when multiple versions of an application are containerized, and each version must be replayed to repeat results. To avoid executing each version separately, CHEX, checkpoints program state and determines when it is permissible to reuse program state across versions. It does so using system call-based execution lineage. It optimizes replay using an in-memory cache, based on a checkpoint-restore-switch system.
CHEX: Multiversion Replay with Ordered Checkpoints. Manne, N. N. Satpati, S. Malik, T. Bagchi, A. Gehani, A. Chaudhary, A. , Proceedings of the Very Large Databases (VLDB), 2022. Paper
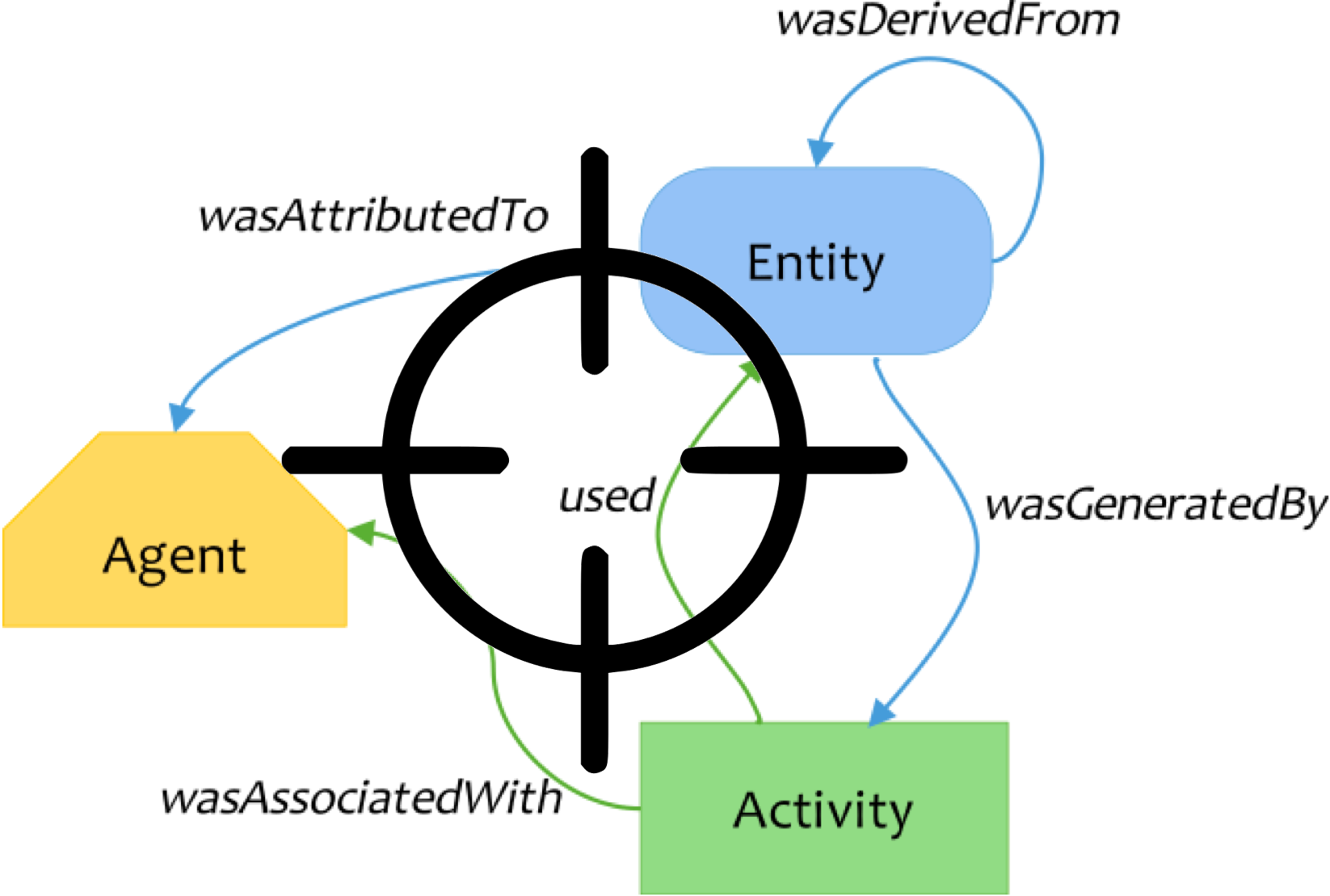
Reproducing experiments entails repeating experiments with changes. Changes, such as a change in input arguments, a change in the invoking environment, or a change due to nondeterminism in the runtime may alter results. If results alter significantly, perusing them is not sufficient—users must analyze the impact of a change and determine if the experiment computed the same steps. Making fine-grained, stepwise comparisons can be both challenging and time-consuming. This project compares a reproduced execution with recorded system provenance of the original execution, and determine provenance alignment. The alignment is based on comparing the specific location in the program, the control flow of the execution, and data inputs.
Efficient provenance alignment in reproduced executions. Nakamura, Y. Malik, T. Gehani, A. , 12th International Workshop on Theory and Practice of Provenance (TaPP 2020), 2020. Paper
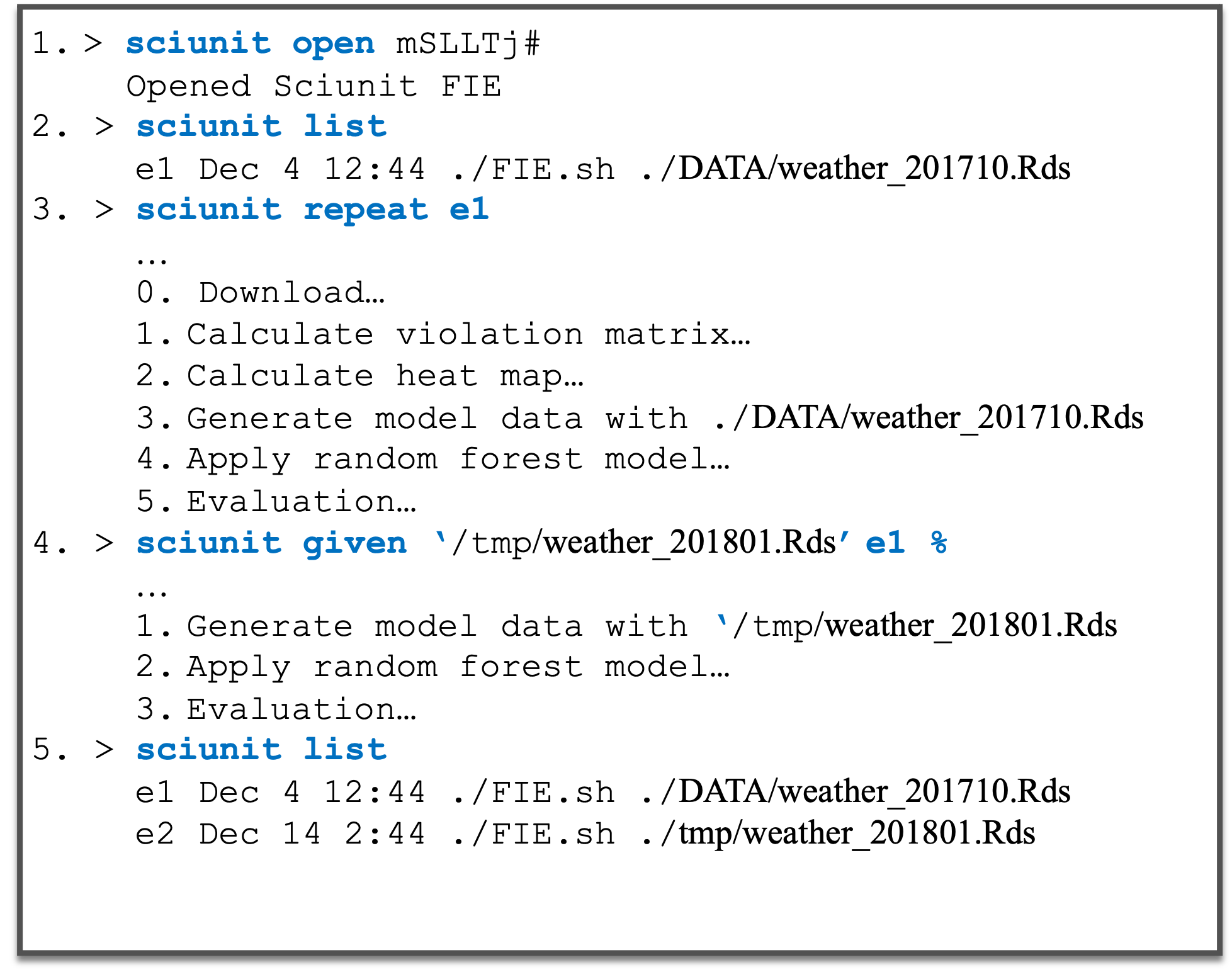
Science is conducted collaboratively, often requiring the sharing of knowledge about computational experiments. When experiments include only datasets, they can be shared using Uniform Resource Identifiers (URIs) or Digital Object Identifiers (DOIs). An experiment, however, seldom includes only datasets, but more often includes software, its past execution, provenance, and associated documentation. The Research Object has recently emerged as a comprehensive and systematic method for aggregation and identification of diverse elements of computational experiments. While a necessary method, mere aggregation is not sufficient for the sharing of computational experiments. Other users must be able to easily recompute on these shared research objects. Computational provenance is often the id to enable such reuse. We show how reusable research objects can utilize provenance to correctly repeat a previous reference execution, to construct a subset of a research object for partial reuse, and to reuse existing contents of a research object for modified reuse.
Utilizing provenance in reusable research objects. Yuan, Z. That, D. H. T. Kothari, S. Fils, G. Malik, T. , Informatics, 2018. Paper
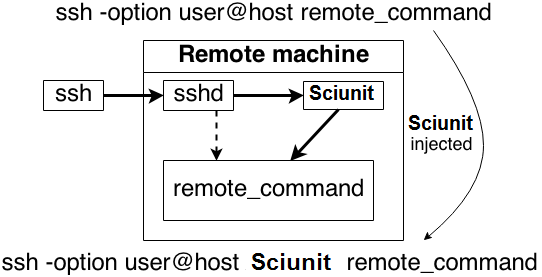
Conference and journal publications increasingly require experiments associated with a submitted article to be repeatable. Authors comply to this requirement by sharing all associated digital artifacts, ie, code, data, and environment configuration scripts. To ease aggregation of the digital artifacts, several tools have recently emerged that automate the aggregation of digital artifacts by auditing an experiment execution and building a portable container of code, data, and environment. However, current tools only package non-distributed computational experiments. Distributed computational experiments must either be packaged manually or supplemented with sufficient documentation.
Improving Reproducibility of Distributed Computational Experiments. Pham, Q. Malik, T. That, D. H. T. Youngdahl, A. , Proceedings of the First International Workshop on Practical Reproducible Evaluation of Computer Systems, 2018. Paper
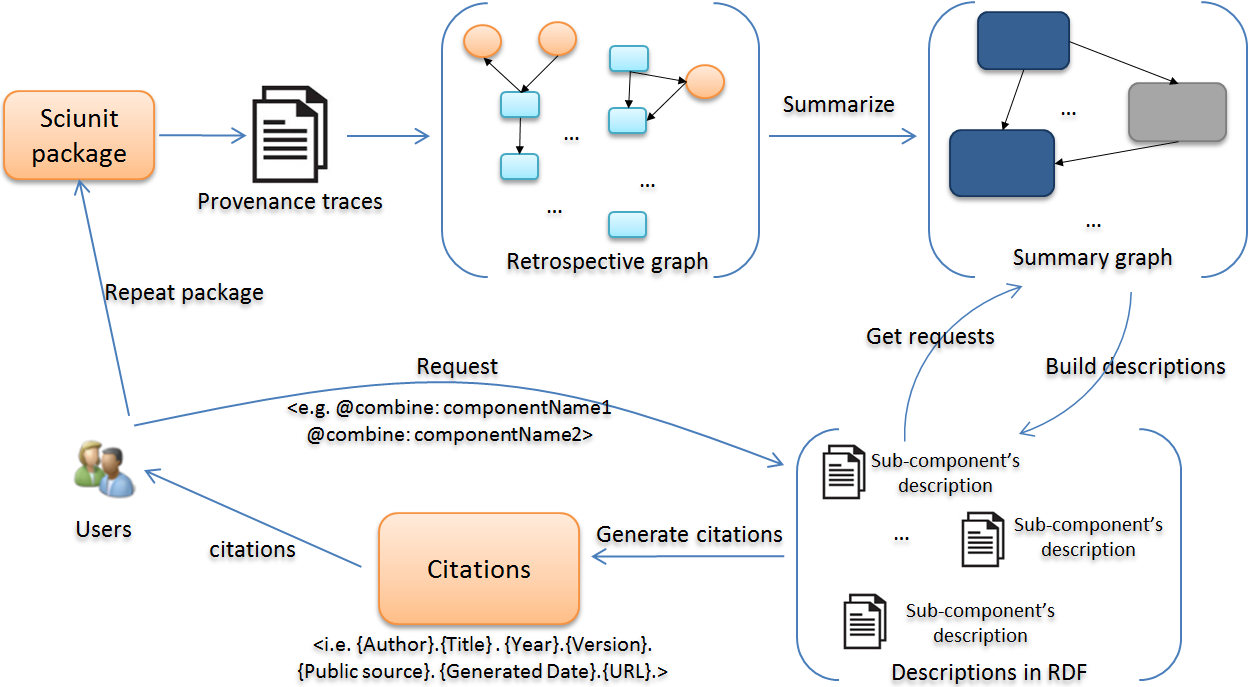
When computational experiments include only datasets, they could be shared through the Uniform Resource Identifiers (URIs) or Digital Object Identifiers (DOIs) which point to these resources. However, experiments seldom include only datasets, but most often also include software, execution results, provenance, and other associated documentation. The Research Object has recently emerged as a comprehensive and systematic method for aggregation and identification of diverse elements of computational experiments. While an entire Research Object may be citable using a URI or a DOI, it is often desirable to cite specific sub-components of a research object to help identify, authorize, date, and retrieve the published sub-components of these objects. We show an approach to automatically generate citations for sub-components of research objects by using the object's recorded provenance.
Using Provenance for Generating Automatic Citations. Malik, T. Rasin, A. Youngdahl, A. 10th USENIX Workshop on the Theory and Practice of Provenance (TaPP 2018), 2018. Paper
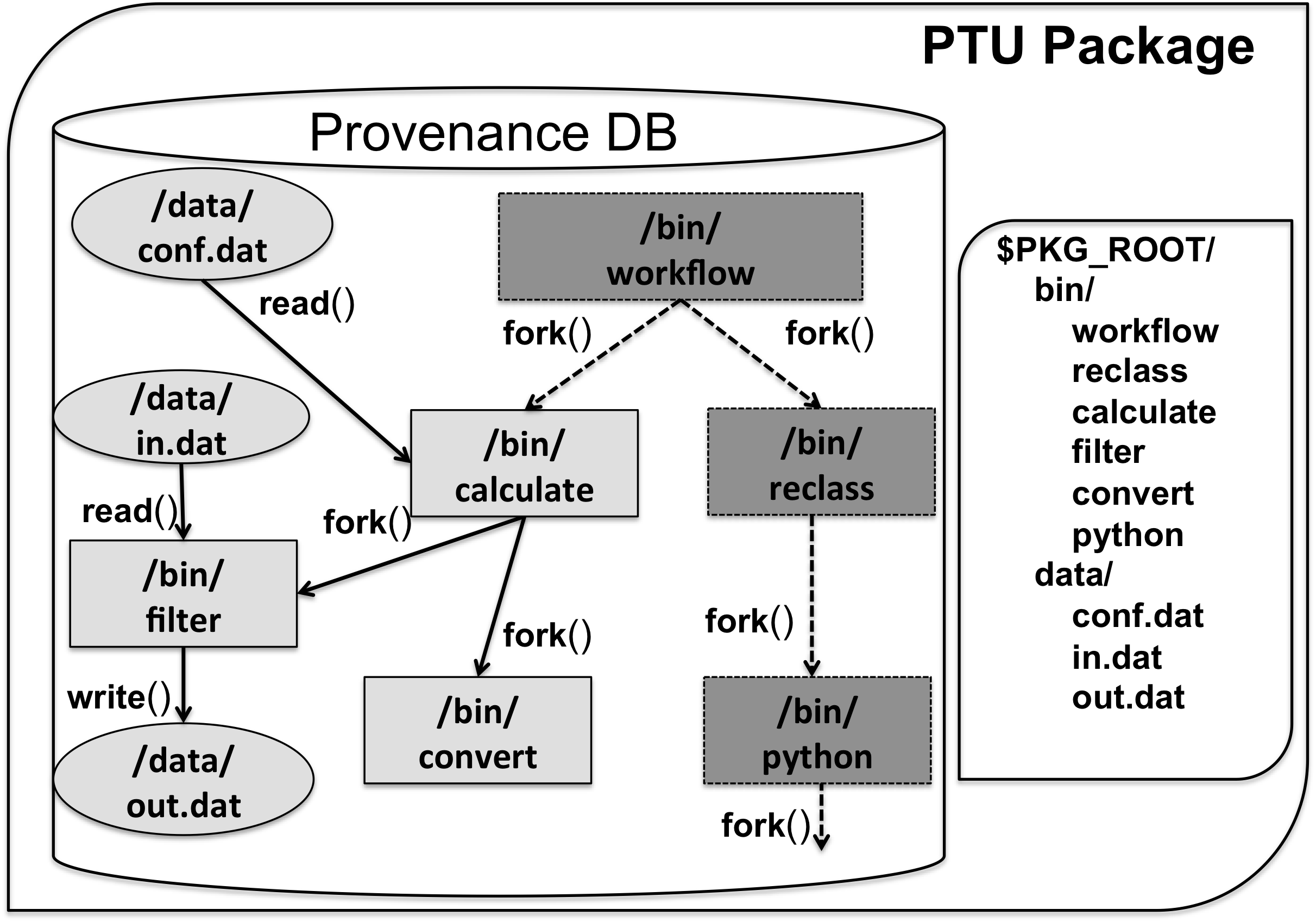
Provenance-To-Use (PTU) is a tool that minimizes computation time during repeatability testing. Authors can use PTU to build a package that includes their software program and a provenance trace of an initial reference execution. Testers can select a subset of the package’s processes for a partial deterministic replay—based, for example, on their compute, memory and I/O utilization as measured during the reference execution. Using the provenance trace, PTU guarantees that events are processed in the same order using the same data from one execution to the next. PTU is now part of Sciunit and helps to conduct repeatability testing of workflow-based scientific programs.
Using provenance for repeatability. Pham, Q. Malik, T. Foster, I. 5th USENIX Workshop on the Theory and Practice of Provenance (TaPP 13), 2013. Paper
This work is supported by the NSF through grants CNS-1846418, ICER-1639759, ICER-1722152, DePaul ORS, and Smart Data Platform:subaward from University of Chicago, Bloomberg Foundation




